
Knowing the center point of your sample data can be very crucial in Statistics. We use the location measures to establish the center of the data, specifically mean, median and mode. Measures of location are mostly used to summarize data using just a single metric value. For example, given the height data of a million people, if they tell you the mean of the heights is six feet, you kind of have a very “good” idea of this distribution of the data.
The most commonly used location measure is the mean, median or the mode. The selection choice on what gets used depends on the scale level of the underlying variable and distribution of the data as well as if there are any outliers in the data. For example, mode is more of nominal scale, median is ordinal (you first order the values in ascending order before splitting them) and median is more of metric scale.
Mean
Mean is simply the average of the data at hand. When we say mean in statistics, most often, we are referring to Arithmetic mean.
Putting it in a Mathematical sense, arithmetic mean or simply mean is the sum of all data points in the provided data, divided by the total number of available data points in the data.
Arithmetic mean can only be computed for metric scale variable types. E.g Height of people, age, blood pressure, temperature, net worth, just to mention a few.
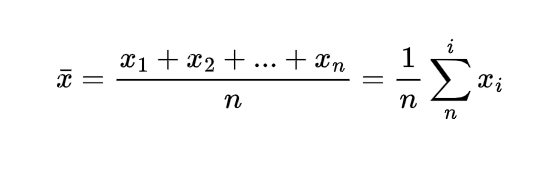
The quadratic mean (also called the root mean square or RMS) is a type of average that emphasizes larger values more than the arithmetic mean does.
Formula
For a set of numbers x₁, x₂, …, xₙ, the quadratic mean is:
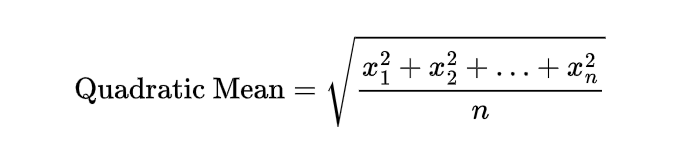
How it works
The process is right in the name:
- Square each value
- Find the mean of those squares
- Take the square root of that mean
Example
For the numbers 3, 4, and 5:
- Square them: 9, 16, 25
- Find the mean: (9 + 16 + 25)/3 = 50/3 ≈ 16.67
- Take the square root: √16.67 ≈ 4.08
Compare this to the arithmetic mean of (3 + 4 + 5)/3 = 4. The quadratic mean is larger because it gives more weight to larger values.
Why it matters
The quadratic mean is useful when:
- Magnitudes matter more than signs — squaring eliminates negatives, so it focuses on size
- You’re dealing with quantities that should be squared — like voltage, current, or velocity in physics
- Larger deviations are more significant — in statistics and signal processing
For instance, electrical engineers use RMS voltage because power is proportional to voltage squared. An AC voltage that alternates between +170V and -170V has an RMS of 120V, which is the DC voltage that would produce the same heating effect.
Geometric Mean
The geometric mean is a type of average that’s particularly useful for rates, ratios, and values that multiply together.
Formula
For a set of numbers x₁, x₂, …, xₙ, the geometric mean is:

Or equivalently:
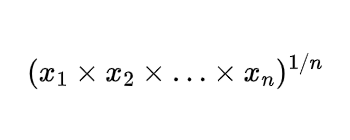
How it works
- Multiply all the values together
- Take the nth root (where n is how many values you have)
Example
For the numbers 2, 8, and 4:
- Multiply them: 2 × 8 × 4 = 64
- Take the cube root (3rd root): ∛64 = 4
Compare this to the arithmetic mean of (2 + 8 + 4)/3 = 4.67. The geometric mean is smaller because it’s less influenced by extreme values.
Why it matters
The geometric mean is the right choice when:
- Dealing with growth rates or percentages — like investment returns over multiple years
- Values are multiplicative rather than additive — things that compound or scale
- Comparing things with different ranges — it handles ratios better than arithmetic mean
Practical example
If your investment grows 50% one year (+50%) and shrinks 20% the next (-20%):
- Wrong approach: Arithmetic mean = (50% + (-20%))/2 = 15% per year
- Right approach: The actual multipliers are 1.5 and 0.8
- Geometric mean = √(1.5 × 0.8) = √1.2 ≈ 1.095
- This means ~9.5% average growth per year, which correctly represents your actual returns
The geometric mean always gives you the true average rate of change for multiplicative processes.
Median
When you order data in increasing order and split it in half right down the middle, the value in the middle is the median. In such a way that half of the values are lower than the median value and the other half of the data is above the median value. So you can think of the median as the “middle value”.
You can only calculate median for data that is ordinal or metric scales, the reason for this is because you have to first order the value in ascending or descending order before splitting it into two halves. The data needs to be ordinally scaled to allow us to compute the ranking and use that to sort the data, without any ranking, then you can not calculate the median, so in this case nominal data can not be used to compute the median. Example of data you can calculate median on are, ages, salaries, grades and number of children.
Even and Odd Number Of Dataset
When your dataset size is an odd number, the median is simply a single value
When the dataset size is an even number, then you’ll get two middle values, the mean of these two values is the median of the data.
Outliers In Dataset
When you have outliers in your dataset, should you compute the mean or median?
The simple answer is that outliers do not have an influence (leverage) on the median, unlike mean that is influenced by the presence of an outlier.
Symmetric Data
When a dataset is normally distributed, the median and the mode will be the same value.
Mode
Model is the number or value in the data set with the largest frequency (most occurrences).
Comparison Of Mean, Mode and Median
Mean, mode, and median are three fundamental measures of central tendency used in statistics to describe the center or typical value of a dataset. Each has distinct characteristics that make it more or less suitable depending on the nature of the data and the presence of outliers.
Definitions
Mean (Arithmetic Average): The sum of all values divided by the number of values. Formula: x̄ = (x₁ + x₂ + … + xₙ)/n
Median: The middle value when data is arranged in order. For even-numbered datasets, it’s the average of the two middle values.
Mode: The value that appears most frequently in the dataset. A dataset can have one mode (unimodal), multiple modes (bimodal or multimodal), or no mode at all.
Impact of Outliers
Mean: Highly sensitive to outliers. A single extreme value can drastically shift the mean away from the typical center of the data. For example, if salaries in a company are $30K, $32K, $35K, $38K, and $500K, the mean ($127K) is misleading because the CEO’s salary pulls it upward.
Median: Resistant to outliers. The median only considers the position of values, not their magnitude. In the salary example above, the median remains $35K, accurately reflecting the typical employee’s salary.
Mode: Unaffected by outliers. The mode depends only on frequency of occurrence, so extreme values have no special influence unless they happen to be the most common value.
Variable Scales and Applicability
Nominal Scale (categorical data with no order): Examples include gender, color, brand names.
- Mean: Not applicable (cannot average categories)
- Median: Not applicable (no meaningful ordering)
- Mode: Best choice (identifies most common category)
Ordinal Scale (ranked categories): Examples include satisfaction ratings (poor, fair, good, excellent), education level, socioeconomic status.
- Mean: Problematic (assumes equal intervals between ranks)
- Median: Appropriate (uses position, not magnitude)
- Mode: Appropriate (identifies most common rank)
Interval/Ratio Scale (metric data with meaningful numerical differences): Examples include temperature, height, weight, income, test scores.
- Mean: Fully appropriate (utilizes all numerical information)
- Median: Appropriate (though doesn’t use all information)
- Mode: Less informative (ignores most data characteristics)
When to Use Each Measure
Use the Mean when:
- Data is measured on an interval or ratio scale
- The distribution is relatively symmetric with no extreme outliers
- You need to use all the data in your calculation
- You plan to perform further statistical analyses (the mean has valuable mathematical properties)
- Examples: average test scores in a class, mean daily temperature, average reaction time in an experiment
Use the Median when:
- Data contains outliers or is skewed
- You want a measure resistant to extreme values
- Data is on an ordinal scale
- You’re dealing with open-ended distributions (like income where the highest category is “$100,000+”)
- Examples: median household income, median home prices, median recovery time for patients
Use the Mode when:
- Data is nominal (categorical)
- You want to identify the most typical or popular category
- Data is discrete with repeated values
- Multiple modes might reveal interesting patterns (bimodal distributions suggest two distinct groups)
- Examples: most common shoe size sold, most frequent customer complaint, most popular product color
Practical Example
Consider a dataset of house prices in a neighborhood: $150K, $155K, $160K, $165K, $170K, $175K, $2.5M
- Mean: $504K (misleading due to mansion)
- Median: $165K (best representation of typical home)
- Mode: None (each value appears once)
In this case, the median provides the most accurate picture of what a typical house costs in the neighborhood. The mean is inflated by the single luxury property, making it a poor choice for describing central tendency.
Conclusion
Congratulations for making it to the end!
Other platforms where you can reach out to me:
Happy coding! And see you next time, the world keeps spinning.